카테고리 없음
ML - Transformer
aspe
2021. 12. 14. 06:02
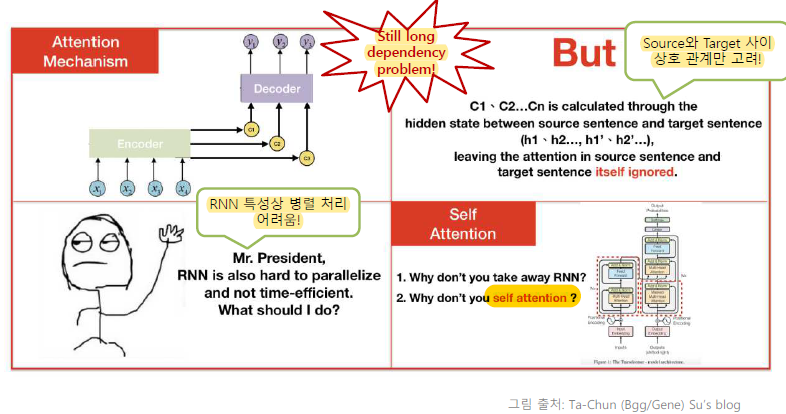
Problems of Attention-Based Models
Because of forget gate, there is still long dependency broblem.
Attention of source sentence and target sentence itself are ignored
RNN is hard to parallelize.
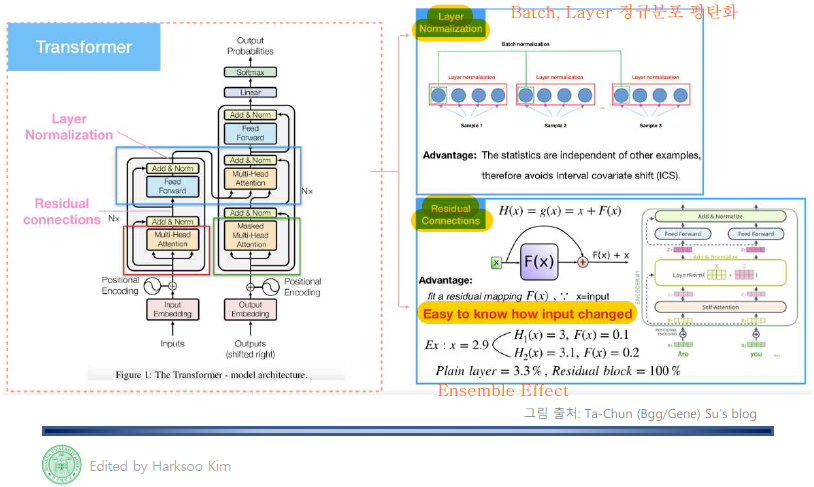
Transformer
It has self attentions of encoder, decoder


Multi-Head Attention
Applying Softmax function to all Query, Key, Value at one time, distinct features are less prominent.
Apply Softmax function with small range several times.

Layer Normalization & Residual Connection
Normalize Layers across batches. -> Avoids Interval Covariate Shift(AIC)
Residual Connection -> Esay to know how input changed, Ensemble effect
Position Encoding
The multi-head attention network cannot naturally make use of the position of the words in the input sequence.
This problem makes same result with different sequence of sentence.
So Transformer has Positional Encoding

All the photos are from Professor Hak-soo Kim's lecture of Konkuk University's Department of Computer Engineering.