
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 롤토체스 api dart
- PlatformException(sign_in_failed
- docker overview
- keychain error
- flutter widget
- 롤 api dart
- valorant api dart
- swift concurrency
- dart.dev
- dart new
- generate parentheses dart
- flutter android 폴더
- tft api dart
- lol api dart
- leetcode dart
- AnimationController
- 파이썬 부동소수점
- flutter bloc
- com.google.GIDSignIn
- flutter
- dart
- swift 동시성
- Architectural overview
- dart new 키워드
- riot api dart
- flutter ios 폴더
- 발로란트 api dart
- flutter statefulwidget
- 파이썬
- widget
Archives
- Today
- Total
aspe
ML - Text Representation 본문
Discrete Representation
- One-hot encoding
- 단어를 벡터로 표현하는 가장 간단한 방법으로 dictionary의 수 만큼 비트수를 만들어서 1을 하나만 갖는 고유한 벡터를 만들어 단어에 할당한다.

- 하지만 엄청난 메모리를 요구하고 유사성의 비교가 불가능하다.
- 단어를 벡터로 표현하는 가장 간단한 방법으로 dictionary의 수 만큼 비트수를 만들어서 1을 하나만 갖는 고유한 벡터를 만들어 단어에 할당한다.
Distributed Representation
- 단어를 문맥에 기반하여 표현하는 방법
- 비슷한 문맥에서 등장하는 단어는 비슷한 의미를 가질것이다.
Co-Occurrence Matrix
- 양 옆에 해당 어절이 몇개나 존재하는지 알려주는 Matrix이다.

Problems with Co-Occurrence Vectors
- Curse of dimensionality
- 차원이 증가하면서 학습데이터의 수가 차원의 수보다 적어서 성능이 저하되는 현상으로 희소 데이터 문제(sparse data problem)이라고도 한다.
특이값 분해 or SVD(Singular Value Decompostion)
- 행렬을 특정한 구조로 분해하는 방식이다.
S가 중요한 정보를 갖고 있다.
From SVD To Word2Vec
- SVD의 문제점
- 계산에 너무 오랜 시간이 소요된다.
- n*m -> O(mn^2)
- 유연성이 너무 떨어진다.
- 새로운 단어가 문서에 추가될 경우에 SVD를 처음부터 다시 수행해야된다.
- 계산에 너무 오랜 시간이 소요된다.
- 해결 방안으로 Word2Vec이 제안되었다.
Word2Vec
Instead of capturing co-occurrence counts directly: Predict surrounding words of every word
Word Embedding
- 단어를 컴퓨터가 구분하기 쉽게 실수 형태의 Vector로 변환하는 과정을 말한다.
- Word Embedding의 결과가 Word VeEmbedding Vector이다.
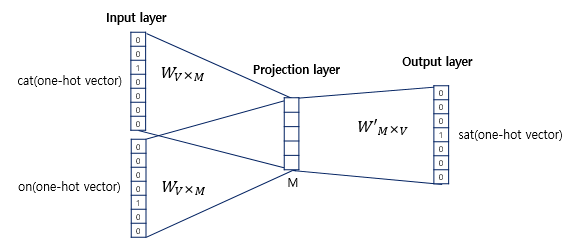
CBOW
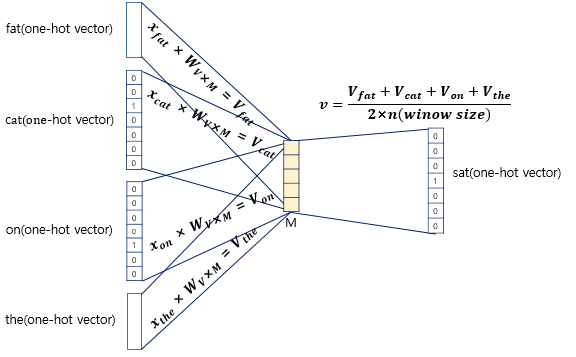
- 기본 아이디어는 여러개의 단어로 하나의 단어를 예측하는 것이다.
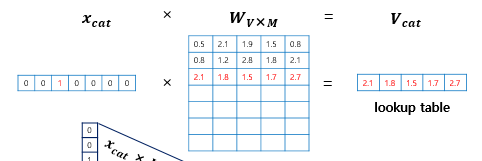
- 은닉층에 활성화 함수가 존재하지 않으며 lookup table이라는 연산을 담당하는 층으로 일반적인 은닉층과 구분히기 위해 Projection layer라고 부른다.
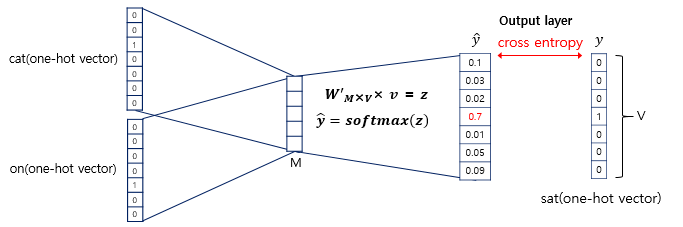
- 아래 4개의 사진을 잘 보면 원리를 쉽게 이해할 수 있다.(사진 출처 : https://wikidocs.net/22660)
Skip-gram
- CBOW와 반대의 메커니즘으로 하나의 단어로 여러개의 주변 단어를 예측하는 것이다.
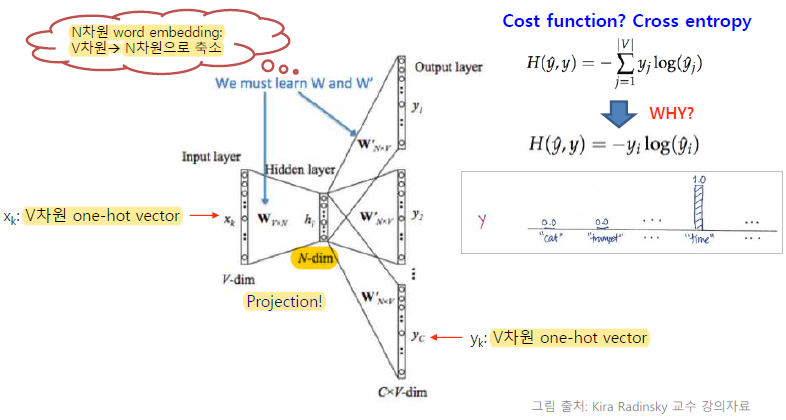
잠시 바로 위의 사진의 Cross Entropy cost function에서 ∑가 사라지는 이유에 대해서 설명하겠다.
아주 간단한데 one-hot vector에 대해 cross entropy를 하므로 yi의 값은 0 또는 1이다. 그리고 1이 되는 단 한 개 뿐이므로 그것에 대한 yi hat만 고려하면 된다.
GloVe(Global Vectors)
기본 아이디어는 단어의 주변만 보고 예측하지 말고 모든(Global) 말뭉치의 확률 값으로 계산하자는 것이다.
더 자세히 설명하면 Embedding 된 중심 단어와 주변 단어 vector의 내적이 전체 corpus에서의 동시 등장 확률이 되도록 만드는 것이다. 즉, 이를 만족하도록 Embedding vector를 만드는 것이 목표이다.

Object Function of GloVe
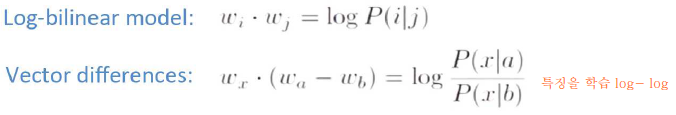
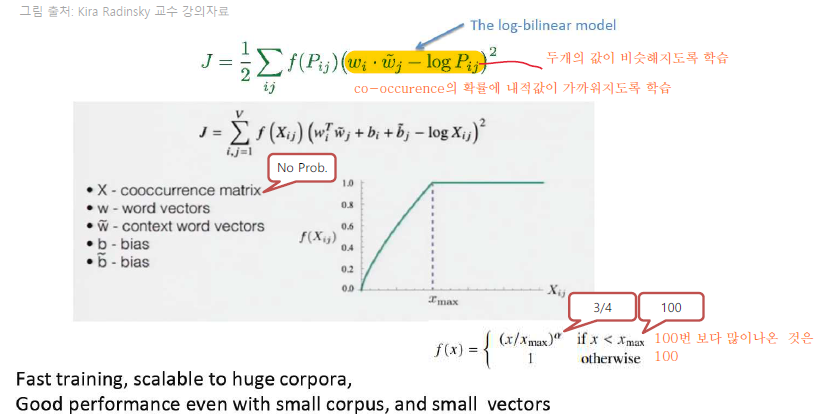
wikidocsl.net의 사진을 제외한 모든 사진의 출처는 건국대학교 컴퓨터공학부 김학수 교수님의 강의자료 일부입니다.
Comments