
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- docker overview
- valorant api dart
- dart new 키워드
- flutter statefulwidget
- swift 동시성
- flutter
- dart.dev
- AnimationController
- tft api dart
- flutter bloc
- 파이썬 부동소수점
- leetcode dart
- 발로란트 api dart
- com.google.GIDSignIn
- widget
- Architectural overview
- flutter widget
- flutter ios 폴더
- lol api dart
- keychain error
- PlatformException(sign_in_failed
- riot api dart
- dart
- 롤토체스 api dart
- dart new
- swift concurrency
- 파이썬
- generate parentheses dart
- 롤 api dart
- flutter android 폴더
Archives
- Today
- Total
aspe
ML - Transformer 본문
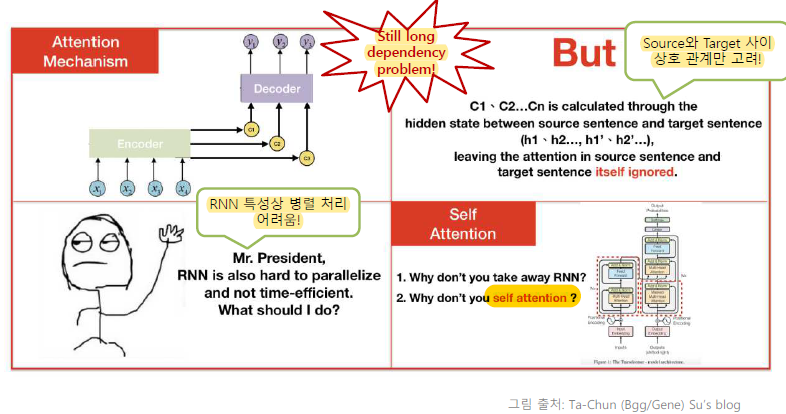
Problems of Attention-Based Models
Because of forget gate, there is still long dependency broblem.
Attention of source sentence and target sentence itself are ignored
RNN is hard to parallelize.
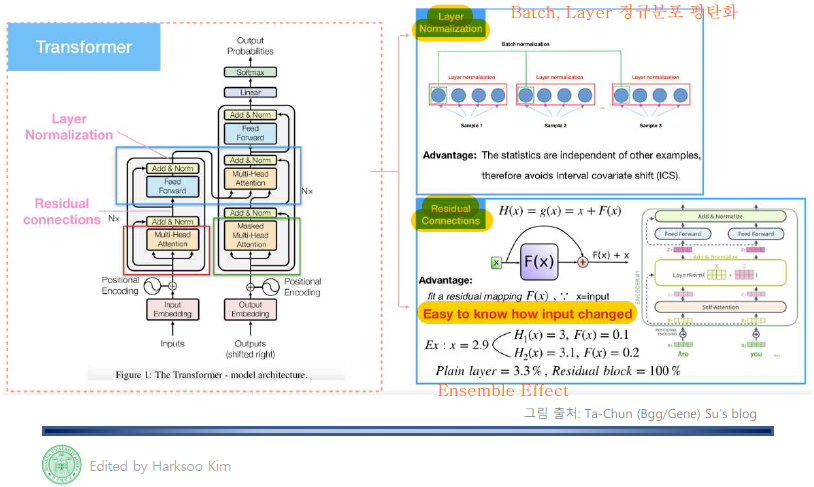
Transformer
It has self attentions of encoder, decoder


Multi-Head Attention
Applying Softmax function to all Query, Key, Value at one time, distinct features are less prominent.
Apply Softmax function with small range several times.

Layer Normalization & Residual Connection
Normalize Layers across batches. -> Avoids Interval Covariate Shift(AIC)
Residual Connection -> Esay to know how input changed, Ensemble effect
Position Encoding
The multi-head attention network cannot naturally make use of the position of the words in the input sequence.
This problem makes same result with different sequence of sentence.
So Transformer has Positional Encoding

All the photos are from Professor Hak-soo Kim's lecture of Konkuk University's Department of Computer Engineering.
Comments